





CPUとGPUの速度比較
Fri Nov 19 20:23:30 JST 2021 (modified: Fri Nov 19 21:04:49 JST 2021)
views: 3387, keywords:GPU, CUDA この記事は最終更新日が4年以上前のものです。
まだCUDAを触り始めて延べ2日なのですが、GPUの速度が気になったので拙いコードで実験してみました。とりあえずGPUがCPUより速いケースを1つ見つけました。
比較するコード
2次元配列の計算を書いた、次の2つのコードを比較します。
- CPUだけ使ったもの(CPU版): https://github.com/ryuichiueda/my_cuda_practice/blob/master/array2d.cpp
- GPUを使ったもの(GPU版): https://github.com/ryuichiueda/my_cuda_practice/blob/master/array2d.cu
計算はこんなものです。Cという配列に、AとBの要素の線型和を何度も足すという、あまり意味のないコードです。
// CPU版のコード(array2d.cpp)
for(int j=0;j<N;j++){
for(int i=0;i<N;i++){
for(int k=0;k<times;k++)
C[i + j*N] += A[i + j*N]*3.14 + B[i + j*N]/3.14;
}
} あとの実験では、N=512で、timesを1, 2, 4, 8, ..., 1024と変化させています。
上のCPU版のコードと同等なCUDAのコードを下に示します。動作は確認していますが、素人工事で、なんで動くかもさっぱりわかりません。あと、N>800でセグメンテーションフォルトを起こします。
// GPU版のコード(array2d.cu)
// この関数が各GPUのコアで並列実行される
__global__ void MatAdd(float *A, float *B, float *C, int times)
{
int block_idx = blockIdx.x*blockDim.x*blockDim.y;
int i = threadIdx.x + blockDim.x * threadIdx.y + block_idx;
for(int k=0;k<times;k++)
C[i] += A[i]*3.14 + B[i]/3.14;
}
int main(int argc, char **argv)
{
(中略)
// ここで実行
MatAdd<<<N, N>>>(a, b, c, times); 上のコードの例では省略しましたが、GPUで計算するときは、メモリの内容をGPUとDRAMでやりとりする処理が必要です。この処理の時間も計測時間に含めます。このコードの場合、timesの回数にかかわらずやりとりはDRAM->GPU1回、GPU->DRAM1回の2回だけなので、timesの回数が増えるほど、メモリの内容のやり取り1回あたりの計算量が増え、GPUの並列処理の効果が見込めるはずです。
実験と結果
先述のようにN=512、timesを1, 2, 4, 8, ..., 1024と変化させて、10回ずつ計算時間を計測しました。そして、10回の計算時間の平均値、標準偏差を求めました。使用したマシンの情報はあとで示します。
CPU版
ざっくり言って、timesあたり1[ms]ずつ比例して増えていきます。
times |
平均計算時間[ms] | 標準偏差[ms] |
|---|---|---|
| 2 | 0.8 | 0.0 |
| 4 | 1.5 | 0.0 |
| 8 | 3.5 | 0.1 |
| 16 | 8.8 | 0.1 |
| 32 | 24.0 | 0.3 |
| 64 | 56.7 | 0.2 |
| 128 | 122.8 | 0.2 |
| 256 | 253.9 | 0.4 |
| 512 | 515.4 | 0.2 |
| 1024 | 1039.9 | 1.1 |
GPU版
GPUの場合は、times=64あたりまではメモリの内容の転送に時間がかかってCPU版より遅いのですが、timesがそれより大きくなるにつれて、CPUよりも処理が早く終わるようになりました。
times |
平均計算時間[ms] | 標準偏差[ms] |
|---|---|---|
| 2 | 55.7 | 4.6 |
| 4 | 54.9 | 3.2 |
| 8 | 56.1 | 9.3 |
| 16 | 54.4 | 2.2 |
| 32 | 55.1 | 1.5 |
| 64 | 57.4 | 2.1 |
| 128 | 62.6 | 3.2 |
| 256 | 71.0 | 5.9 |
| 512 | 89.0 | 8.9 |
| 1024 | 125.7 | 13.8 |
メモリの内容の転送に55[ms]かかるとすると、計算にはだいたいtimes1回あたり、0.06[ms]から0.07[ms]くらいかかっていることが表の数字から分かります。CPUでは1[ms]だったので、14〜17倍の速度で計算できたことになります。CPUのコアを複数使って並列処理をすればもうちょっとこの差は縮みますが、少なくともGPUがCPUと同等の演算装置になりうるということが分かりました。
上のGPU版のコードも、コアは全部使っていないような気がするのでもっと差が開くかもしれませんが、それはまだ素人なのでよく分かりません。余裕があればN=800とかでやってみます。
おわりに
正直、これを研究のアルゴリズムに対してどう使うかは、まださっぱり頭に思い浮かばないのですが、なんとか模索したいところです。
付録: 計算機のスペック
- CPU
$ cat /proc/cpuinfo | head -n 9
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 165
model name : Intel(R) Core(TM) i9-10885H CPU @ 2.40GHz
stepping : 2
microcode : 0xea
cpu MHz : 1339.260
cache size : 16384 KB- GPU
$ nvidia-smi
Fri Nov 19 20:57:22 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Quadro T2000 wi... Off | 00000000:01:00.0 Off | N/A |
| N/A 49C P5 8W / N/A | 926MiB / 3911MiB | 1% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
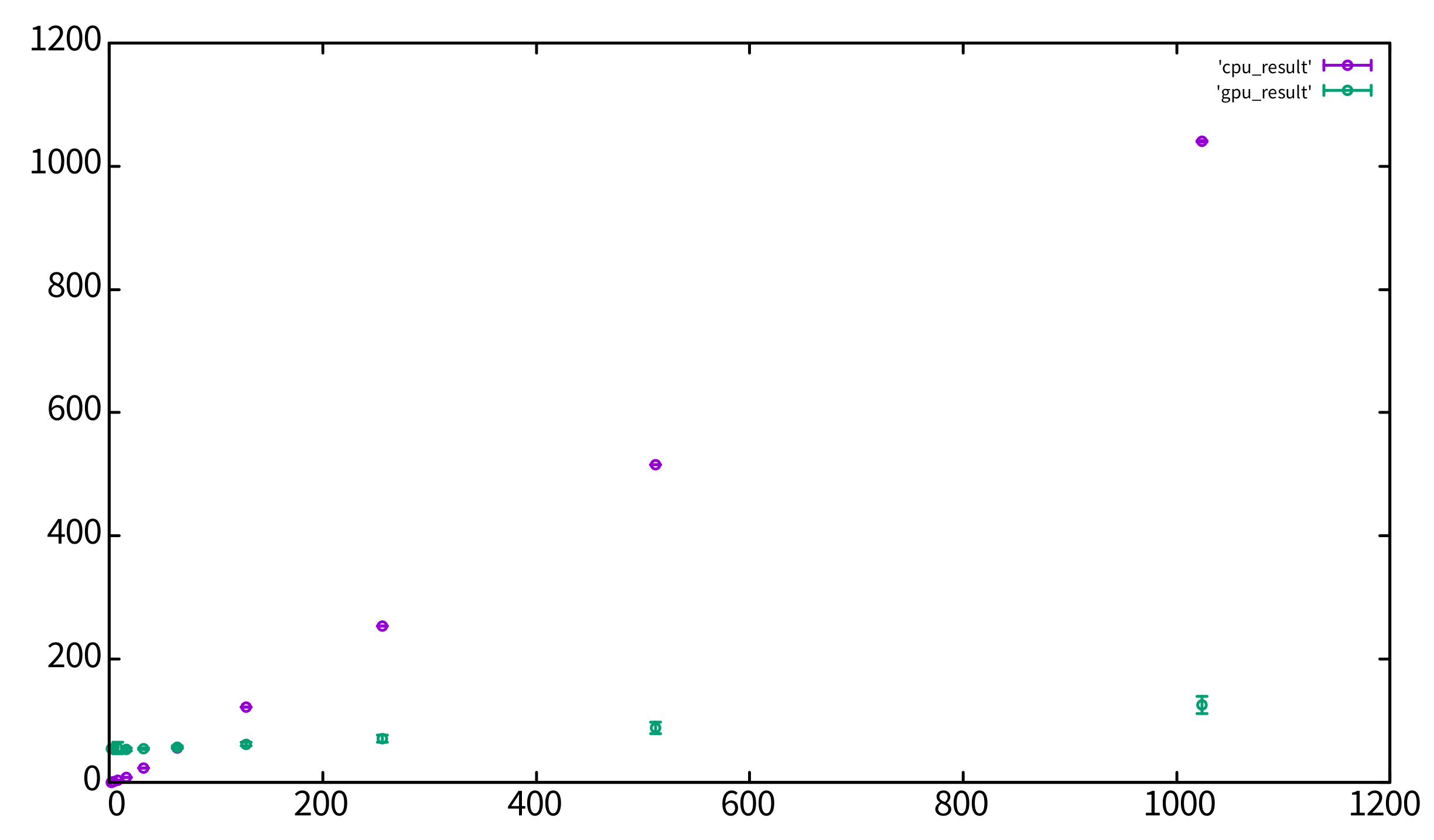
(以下略)付録: 上の表をグラフにしたもの
横軸がtimes、縦軸が時間[ms]です。紫色の印がCPU、緑色の印がGPUのデータです。
 ノート
Tweet
ノート
Tweet