





Excelファイルをシェル芸でほじくる。ただしエクセル方眼紙は後日ということで。
Wed Mar 26 23:22:07 JST 2014 (modified: Sat Sep 30 16:15:34 JST 2017)
views: 6155, keywords:xlsx,寝る,エクセル方眼紙もお任せ!,シェル芸,エクシェル芸 この記事は最終更新日が8年以上前のものです。
追記:続編書きました
だっこした子供が寝てしまってキーボードを叩くしかやることがない上田ですこんばんわ。
最近エクセル方眼紙がブームです。シェル芸人としては便乗するしかありません。ちょっとエクセルのファイルに悪戯してみます。皆さんも手を動かしてみてください。
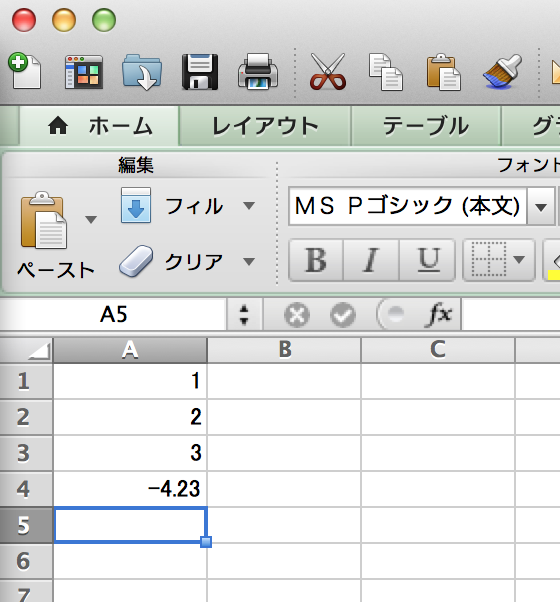
まず上に挙げたエクセルファイルを用意して、book.xlsxと名前とつけます。セルにはとりあえず数字だけ書きましょう。文字列がある場合はまた後日。
こんな風に適当なディレクトリに置いてください。
uedambp:tmp ueda$ pwd
/Users/ueda/tmp
uedambp:tmp ueda$ ls
book.xlsx次にやるのは「解凍」です。実は.xlsxはzipファイルです。
uedambp:tmp ueda$ unzip book.xlsx
Archive: book.xlsx
inflating: [Content_Types].xml
inflating: _rels/.rels
inflating: xl/_rels/workbook.xml.rels
inflating: xl/workbook.xml
extracting: docProps/thumbnail.jpeg
inflating: xl/theme/theme1.xml
inflating: xl/styles.xml
inflating: xl/worksheets/sheet1.xml
inflating: docProps/core.xml
inflating: docProps/app.xml 解凍するとこんなディレクトリツリーが出現します。エロいですね。(何が?)
uedambp:tmp ueda$ tree
.
├── [Content_Types].xml
├── _rels
├── book.xlsx
├── docProps
│ ├── app.xml
│ ├── core.xml
│ └── thumbnail.jpeg
└── xl
├── _rels
│ └── workbook.xml.rels
├── styles.xml
├── theme
│ └── theme1.xml
├── workbook.xml
└── worksheets
└── sheet1.xml
6 directories, 10 filessheet1.xmlを見てみましょう。
uedambp:tmp ueda$ cat xl/worksheets/sheet1.xml
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet
xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relations
hips" xmlns:mc="http://schemas.openxmlformats.org/markup-
compatibility/2006" mc:Ignorable="x14ac"
xmlns:x14ac="http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac"
><dimension ref="A1:A4"/><sheetViews><sheetView tabSelected="1"
workbookViewId="0"><selection activeCell="A5" sqref="A5"/></sheetView>
</sheetViews><sheetFormatPr baseColWidth="12" defaultRowHeight="18"
x14ac:dyDescent="0"/><sheetData><row r="1" spans="1:1"><c r="A1">
<v>1</v></c></row><row r="2" spans="1:1"><c r="A2"><v>2</v></c></row>
<row r="3" spans="1:1"><c r="A3"><v>3</v></c></row><row r="4"
spans="1:1"><c r="A4"><v>-4.2300000000000004</v></c></row></sheetData>
<phoneticPr fontId="1"/><pageMargins left="0.7" right="0.7" top="0.75"
bottom="0.75" header="0.3" footer="0.3"/><extLst><ext uri="{64002731-A6B0-
56B0-2670-7721B7C09600}"
xmlns:mx="http://schemas.microsoft.com/office/mac/excel/2008/main">
<mx:PLV Mode="0" OnePage="0" WScale="0"/></ext></extLst>
</worksheet>uedambp:tmp ueda$ 嫌がらせ
[ad#articleheader]
数字はcという名前の要素に入っています。抽出してみましょう。POSIXにうるさい方々には叱られそうですが・・・。
uedambp:tmp ueda$ cat xl/worksheets/sheet1.xml |
grep -o '<c [^<]*><v>[^<]*</v></c>'
<c r="A1"><v>1</v></c>
<c r="A2"><v>2</v></c>
<c r="A3"><v>3</v></c>
<c r="A4"><v>-4.2300000000000004</v></c>あとは余計な記号を除去してセルの番号と数字を取り出します。
uedambp:tmp ueda$ cat xl/worksheets/sheet1.xml |
grep -o '<c [^<]*><v>[^<]*</v></c>' | tr '><"' ' ' | awk '{print $3,$5}'
A1 1
A2 2
A3 3
A4 -4.2300000000000004ぜひやってみてください。案外使える技かもしれません。
文字列や数式が入っている場合についてはまた後日。
寝る。
 ノート
Tweet
ノート
Tweet